
This is a cross-post with the cyberia computer club blog.
Previous post in this series: Capsul Rollin' Onwards with a Web Application
What is this?
If you're a wondering "what is capsul?", see:
Here's a quick summary of what's in this post:
-
cryptocurrency payments are back
-
we visited the server in person for maintenance
-
most capsuls disks should have trim/discard support now, so you can run the fstrim command to optimize your capsul's disk. (please do this, it will save us a lot of disk space!!)
-
we updated most of our operating system images and added a new rocky linux image!
-
potential ideas for future development on capsul
-
exciting news about a new server and a new capsul fork being developed by co-op cloud / servers.coop
What happened to the cryptocurrency payment option?
Life happens. Cyberia Computer Club has been hustling and bustling to build out our new in-person space in Minneapolis, MN:
https://wiki.cyberia.club/hypha/cyberia_hq/faq
Hackerspace, lab, clubhouse, we aren't sure what to call it yet, but we're extremely excited to finish with the renovations and move in!
In the meantime, something went wrong with the physical machine hosting our BTCPay server and we didn't have anywhere convenient to move it, nor time to replace it, so we simply disabled cryptocurrency payments temporarily in September 2021.
Many of yall have emailed us asking "what gives??", and I'm glad to finally be able to announce that
"the situation has been dealt with",
we have a brand new server and the blockchain syncing process is complete, cryptocurrency payments in bitcoin, litecoin, and monero are back online now!
--> https://capsul.org/payment/btcpay <--
Also, fun fact, the BTCPay server is currently located at my house, but I didn't have a good way to expose it to the internet, so I simply pointed the btcpay.cyberia.club domain at my greenhouse subdomain
root@beet:~# nslookup btcpay.cyberia.club
Server: 127.0.0.53
Address: 127.0.0.53#53
Non-authoritative answer:
btcpay.cyberia.club canonical name = forest.greenhouseusers.com.
Name: forest.greenhouseusers.com
Address: 68.183.194.212
Then published the server to the internet thru greenhouse!
root@beet:~# greenhouse tunnel https://btcpay.cyberia.club to tcp://localhost:3000
Now applying new tunnel configuration...
- waiting for underlying services to start
- creating threshold tunnels
- testing threshold tunnels
- configuring caddy
- waiting for caddy to obtain https certificates from Let's Encrypt
- final testing
Your tunnel was configured successfully!
That one time capsul was almost fsync()'d to death
Guess what? Yall loved capsul so much, you wore our disks out. Well, almost.
We use redundant solid state disks + the ZFS file system for your capsul's block storage needs, and it turns out that some of our users like to write files. A lot.
Over time, SSDs will wear out, mostly dependent on how many writes hit the disk. Baikal, the server behind capsul.org, is a bit different from a typical desktop computer, as it hosts about 100 virtual machines, each with thier own list of application processes, for over 50 individual capsul users, each of whom may be providing services to many other individuals in turn.
The disk-wear-out situation was exacerbated by our geographical separation from the server; we live in Minneapolis, MN, but the server is in Georgia. We wanted to install NVME drives to expand our storage capacity ahead of growing demand, but when we would mail PCI-e to NVME adapters to CyberWurx, our datacenter colocation provider, they kept telling us the adapter didn't fit inside the 1U chassis of the server.
At one point, we were forced to take a risk and undo the redundancy of the disks in order to expand our storage capacity and prevent "out of disk space" errors from crashing your capsuls. It was a calculated risk, trading certain doom now for the potential possibility of doom later.
Well, time passed while we were busy with other projects, and those non-redundant disks started wearing out. According to the "smartmon" monitoring indicator, they reached about 25% lifespan remaining. Once the disk theoretically hit 0%, it would become read-only in order to protect itself from total data loss. So we had to replace them before that happened.
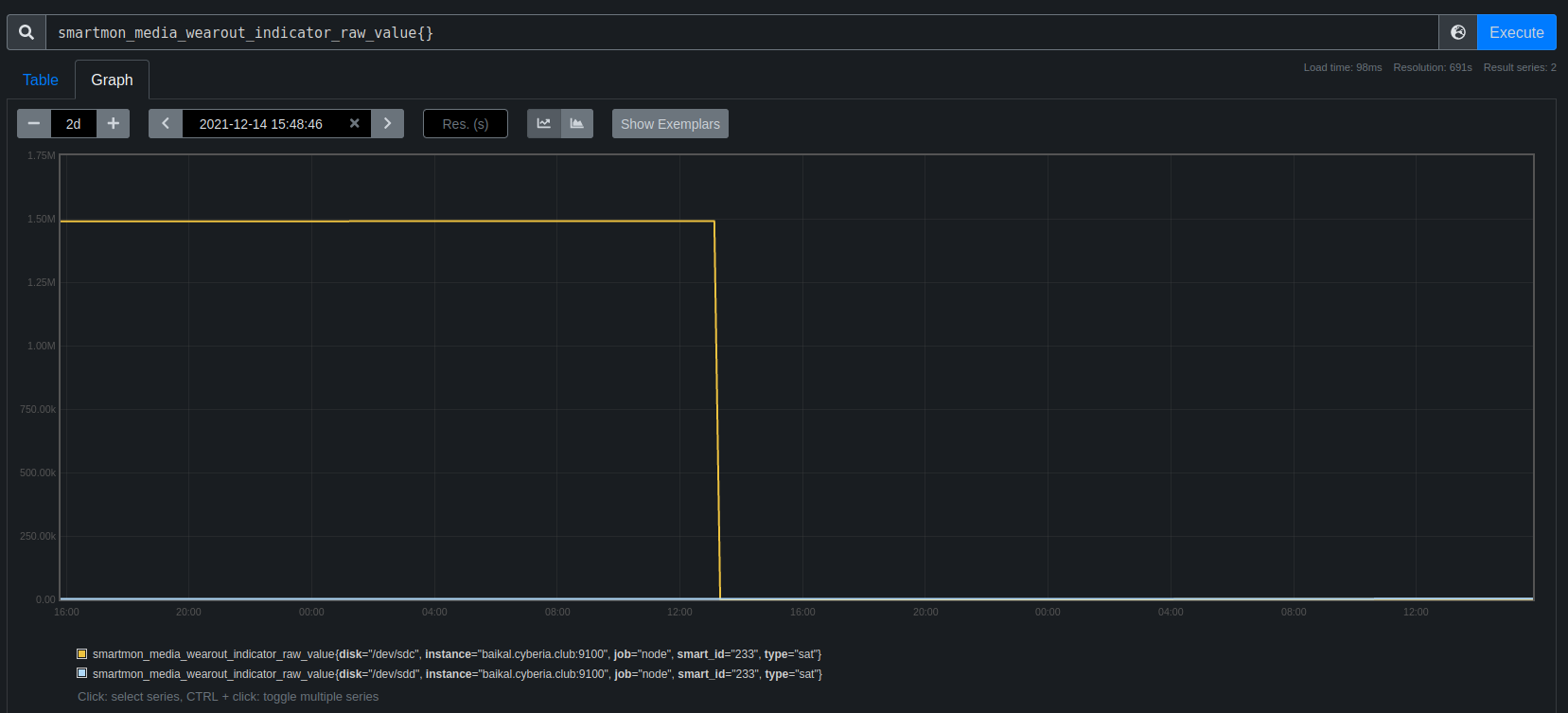
We were so scared of what could happen if we slept on this that we booked a flight to Atlanta for maintenance. We wanted to replace the disks in person, and ensure we could restore the ZFS disk mirroring feature.
We even custom 3d-printed a bracket for the tiny PCI-e NVME drive that we needed in order to restore redundancy for the disks, just to make 100% sure that the maintenance we were doing would succeed & maintain stability for everyone who has placed thier trust in us and voted with thier shells, investing thier time and money on virtual machines that we maintain on a volunteer basis.

Unfortunately, "100% sure" was still not good enough, the new NVME drive didn't work as a ZFS mirroring partner at first — the existing NVME drive was 951GB, and the one we had purchased was 931GB. It was too small and ZFS would not accept that. f0x suggested:
[you could] start a new pool on the new disk, zfs send all the old data over, then have an equally sized partition on the old disk then add that to the mirror
But we had no idea how to do that exactly or how long it would take & we didn't want to change the plan at the last second, so instead we ended up taking the train from the datacenter to Best Buy to buy a new disk instead.
The actual formatted sizes of these drives are typically never printed on the packaging or even mentioned on PDF datasheets online. When I could find an actual number for a model, it was always the lower 931GB. So, we ended up buying a "2TB" drive as it was the only one BestBuy had which we could guarantee would work.
So, lesson learned the hard way. If you want to use ZFS mirroring and maybe replace a drive later, make sure to choose a fixed partition size which is slightly smaller than the typical avaliable space on the size of drive you're using, in case the replacement drive was manufactured with slightly less avaliable formatted space!!!
Once mirroring was restored, we made sure to test it in practice by carefully removing a disk from the server while it's running:
While we could have theoretically done this maintenance remotely with the folks at CyberWurx performing the physical parts replacement per a ticket we open with them, we wanted to be sure we could meet the timeline that the disks had set for US. That's no knock on CyberWurx, moreso a knock on us for yolo-ing this server into "production" with tape and no test environment :D
The reality is we are vounteer supported. Right now the payments that the club receives from capusl users don't add up to enough to compensate (make ends meet for) your average professional software developer or sysadmin, at least if local tech labor market stats are to be believed.
We are all also working on other things, we can't devote all of our time to capsul. But we do care about capsul, we want our service to live, mostly because we use it ourselves, but also because the club benefits from it.
We want it to be easy and fun to use, while also staying easy and fun to maintain. A system that's agressively maintained will be a lot more likely to remain maintained when it's no one's job to come in every weekday for that.
That's why we also decided to upgrade to the latest stable Debian major version on baikal while we were there. We encountered no issues during the upgrade besides a couple of initial omissions in our package source lists. The installer also notified us of several configuration files we had modified, presenting us with a git-merge-ish interface that displayed diffs and allowed us to decide to keep our changes, replace our file with the new version, or merge the two manually.
I can't speak more accurately about it than that, as j3s did this part and I just watched :)
Looking to the future
We wanted to upgrade to this new Debian version because it had a new major version of QEMU, supporting virtio-blk storage devices that can pass-through file system discard commands to the host operating system.
We didn't see any benefits right away, as the vms stayed defined in libvirt as their original machine types, either pc-i440fx-3.1 or a type from the pc-q35 family.
After returning home, we noticed that when we created a new capsul, it would come up as the pc-i440fx-5.2 machine type and the main disk on the guest would display discard support in the form of a non-zero DISC-MAX size displayed by the lsblk -D command:
localhost:~# sudo lsblk -D
NAME DISC-ALN DISC-GRAN DISC-MAX DISC-ZERO
sr0 0 0B 0B 0
vda 512 512B 2G 0
Most of our capsuls were pc-i440fx ones, and we upgraded them to pc-i440fx-5.2, which finally got discards working for the grand majority of capsuls.
If you see discard settings like that on your capsul, you should also be able to run fstrim -v / on your capsul which saves us disk space on baikal:
welcome, cyberian ^(;,;)^
your machine awaits
localhost:~# sudo lsblk -D
NAME DISC-ALN DISC-GRAN DISC-MAX DISC-ZERO
sr0 0 0B 0B 0
vda 512 512B 2G 0
localhost:~# sudo fstrim -v /
/: 15.1 GiB (16185487360 bytes) trimmed
^ Please do this if you are able to!
You might also be able to enable an fstrim service or timer which will run fstrim to clean up and optimize your disk periodically.
However, some of the older vms were the pc-q35 family of QEMU machine type, and while I was able to get one of ours to upgrade to pc-i440fx-5.2, discard support still did not show up in the guest OS. We're not sure what's happening there yet.
We also improved capsul's monitoring features; we began work on proper infrastructure-as-code-style diffing functionality, so we get notified if any key aspects of your capsuls are out of whack. In the past this had been an issue, with DHCP leases expiring during maintenance downtimes and capsuls stealing each-others assigned IP addresses when we turn everything back on.
capsul-flask now also includes an admin panel with 1-click-fix actions built in, leveraging this data:
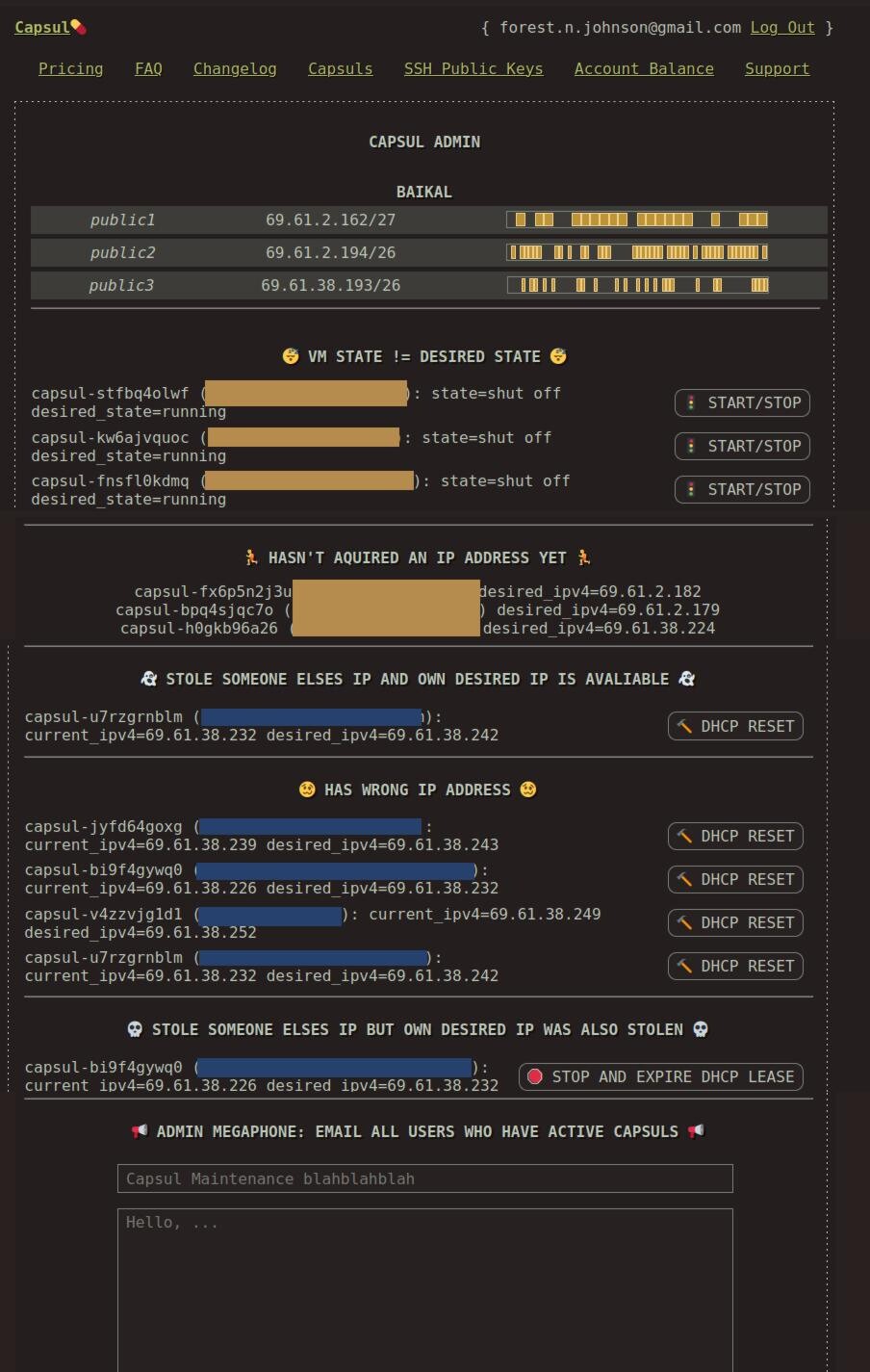
I acknowledge that this is a bit of a silly system, but it's an artifact of how we do what we do. Capsul is always changing and evolving, and the web app was built on the idea of simply "providing a button for" any manual action that would have to be taken, either by a user or by an admin.
At one point, back when capsul was called "cvm", everything was done by hand over email and the commandline, so of course anything that reduced the amount of manual administration work was welcome, and we are still working on that today.
When we build new UIs and prototype features, we learn more about how our system works, we expand what's possible for capsul, and we come up with new ways to organize data and intelligently direct the venerable virtualization software our service is built on.
I think that's what the "agile development" buzzword from professional software development circles was supposed to be about: freedom to experiment means better designs because we get the opportunity to experience some of the consequences before we fully commit to any specific design. A touch of humility and flexibility goes a long way in my opinion.
We do have a lot of ideas about how to continue making capsul easier for everyone involved, things like:
-
Metered billing w/ stripe, so you get a monthly bill with auto-pay to your credit card, and you only pay for the resources you use, similar to what service providers like Backblaze do. (Note: of course we would also allow you to pre-pay with cryptocurrency if you wish)
-
Looking into rewrite options for some parts of the system: perhaps driving QEMU from capsul-flask directly instead of going through libvirt, and perhaps rewriting the web application in golang instead of sticking with flask.
-
JSON API designed to make it easier to manage capsuls in code, scripts, or with an infrastructure-as-code tool like Terraform.
-
IO throttling your vms: As I mentioned before, the vms wear out the disks fast. We had hoped that enabling discards would help with this, but it appears that it hasn't done much to decrease the growth rate of the smartmon wearout indicator metric. So, most likely we will have to enforce some form of limit on the amount of disk writes your capsul can perform while it's running day in and day out. 80-90% of capsul users will never see this limit, but our heaviest writers will be required to either change thier software so it writes less, or pay more money for service. In any case, we'll send you a warning email long before we throttle your capsul's disk.
And last but not least, Cybera Computer Club Congress voted to use a couple thousand of the capsulbux we've recieved in payment to purchase a new server, allowing us to expand the service ahead of demand and improve our processes all the way from hardware up.
(No tape this time!)
Shown: Dell PowerEdge R640 1U server with two 10-core xeon silver 4114 processors and 256GB of RAM. (Upgradable to 768GB!!)
Can I help?
Yes! We are not the only ones working on capsul these days. For example, another group, https://coopcloud.tech has forked capsul-flask and set up thier own instance at

Thier source code repository is here (not sure this is the right one):
https://git.autonomic.zone/3wordchant/capsul-flask
Having more people setting up instances of capsul-flask really helps us, whether folks are simply testing or aiming to run it in production like we do.
Unfortunately we don't have a direct incentive to work on making capsul-flask easier to set up until folks ask us how to do it. Autonomic helped us a lot as they made thier way through our terrible documentation and asked for better organization / clarification along the way, leading to much more expansive and organized README files.
They also gave a great shove in the right direction when they decided to contribute most of a basic automated testing implementation and the beginnings of a JSON API at the same time. They are building a command line tool called abra that can create capsuls upon the users request, as well as many other things like installing applications. I think it's very neat :)
Also, just donating or using the service helps support cyberia.club, both in terms of maintaing capsul.org and reaching out and supporting our local community.
We accept donations via either a credit card (stripe) or in Bitcoin, Litecoin, or Monero via our BTCPay server:
For the capsul source code, navigate to:
https://git.cyberia.club/cyberia/capsul-flask
As always, you may contact us at:
Or on matrix:
#services:cyberia.club
For information on what matrix chat is and how to use it, see https://cyberia.club/matrix
Previous post in this series: Capsul Rollin' Onwards with a Web Application
Comments