
This post is part of a new experiment; I'm toying with the idea of writing a concise and approachable "folk textbook" covering the conceptual basics of what I do; using Linux and other operating systems like MacOS and Windows, home routers, networking software, servers, virtual machines, linux containers, etc. I'm starting out by writing a few drafts or tidbits in this style as blog articles.
I actually started out on this path when I was writing on a different subject, but I got stuck halfway through: I wanted to mention processes and process exit codes, but I couldn't come up with any high-quality primary sources to cite. As far as I can tell, neither wikipedia nor the linux man pages (linux manual) contain a concise definition of what a process is including it's common features, i.e. things that every process has / things that every process can do.
I know I've mentioned linux a lot here, but I'd like to emphasize that this article is about processes in all major desktop and mobile phone operating systems, including Windows, and the similarities that they have.
Folks on the cyberia.club matrix server suggested an operating systems textbook...

what would you consider a primary source for this information ?
what is a process exit code / what's the anatomy of a process, what things does a process have / what does it do?
I can't find anything on for example the man pages 😦
Argh. this is hilarious to me that this crucial conceptual information is not even written down in a public online place outside of anecdotes

A comp sci textbook, perhaps?
its easy to find textbook pdfs online but they are kinda crap for what I want because
- the information is presented in book form and IMO no one wants to read like that any more
- you can't make a hyperlink to a section in a PDF afaik
- they aren't good for linking to anywasy because they aren't permanent because of copyright claims
... but what I really wanted was something I could link to. So...
here weeee gooooo! (If you notice any factual innacuracies in this article, please let me know or leave a comment below!)
Table of Contents
- Overview of Processes
- The Typical "Create Process" Options
- Typical Features of a Running Process
- After a Process Exits
Overview of Processes
All typical operating systems (MacOS, Windows, Linux, BSD, and others) have a notion of a "Process", and there are far more similarities than differences between the ways that these different OSes implement processes.
When you launch a program (For example, by clicking on that program in the Start Menu (Windows), or Dock (MacOS / Ubuntu Linux), you are instructing the operating system on your computer to launch a new process in order to run the program you clicked on.
There are two other common ways to launch a process on a computer:
- In an interactive shell or "command line" —
cmd.exe(Windows) orbash/zsh(Linux/MacOS) — every command that you run creates a process. - If you are writing your own program, it's almost certain that the programming language you are using includes some
process.Start()functionality in its standard library. Such a function will spawn a new process in the operating system, typically a subprocess of the process calling the function.
Programs running as processes on your computer may perform arbitrary computations, but in order to make themselves useful they'll also need to interact with your computer hardware. For example, to respond to mouse and keyboard input, display pixels on the screen, read and write files, and connect to other computers on the internet.
In order to increase stability, security, and performance, all modern operating systems separate processes from the hardware and from each-other.
Process A is not allowed to read or write data used by Process B.
Any given process is not allowed to directly touch the screen, disk, or network. Instead, it must ask the operating system to do those things on its behalf. This is called a "system call" or "syscall".
Once started, a process will run either until the loaded program calls the exit() syscall, or until the process is forcefully killed by the operating system.
When it comes to creation of new processes, the syscalls involved, fork() and exec(), are much more complex. Typically, programmers interact with these syscalls through a more simplified process API in their language of choice.
The Typical "Create Process" Options
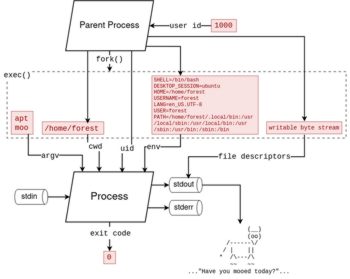
When we wish to start a new process, whether we do it by clicking on an application icon, running a command, or in our code, there are many settings being applied to that new process. Depending on how the process is launched, it may or may not be possible for you to control all of these settings, but it's important to understand that they always can be specified, you just have to figure out how.
Which Program to Run
First, we need to tell the operating system which executable file (program) we want it to run.
In many cases, like when running a command inside a shell, we can simply provide the name of a program, and the full file path of that program's executable file will be automatically resolved for us via the PATH environment variable.
🤔 Example: In my Linux
bashshell, when I typeapt moo, the shell
- looks into the
PATHvariable
- The value of
PATHlooks something like this:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin- searches each folder mentioned in the
PATHvariable
- It's a list of folders separated by colons (
:)
- /usr/local/sbin
- /usr/local/bin
- /usr/sbin
- /usr/bin
- /bin
- resolves to the first file called
aptinside one of those folders
- you can see this in action with the
whichcommand on MacOS/Linux orwherecommand on Windows:
which apt→/usr/bin/aptwhere wmic→C:\Windows\System32\wbem\WMIC.exe- Spawns a new process running the
/usr/bin/aptexecutable binary file withmooas the first and only program argument, invoking the "Super Cow Powers" apt easter egg:forest@thingpad:~$ apt moo (__) (oo) /------\/ / | || * /\---/\ ~~ ~~ ..."Have you mooed today?"...
Running programs in the current working directory
On windows, if you are in a folder which contains program.exe and you run program.exe in your windows terminal, it will run program.exe as you expect. But not so on linux or Mac OS. These unix-ish OSes will always go for the $PATH-based resolution process by default, but you can override this by specifying the command you want to run as a file path rather than a bare word. So, you could either give the full file path /users/me/Desktop/programs/example, or if you are already inside the /users/me/Desktop/programs folder, you could use a relative file path: ./example. I believe this was security-motivated default behaviour in unix, and it's been passed down to linux and mac.
Program Arguments
Arguments are meant to tell the program what to do or how to run, the name "argument" comes from math terminology for functions, for example, in f(x, y), x and y are called the arguments of the function f.
In this case, f is our program, and x is the first argument, y is the second argument.
ℹ️ NOTE: when writing program code or scripts, the "Which Program to Run" and "Program Arguments" information is often combined into a single list or array called
arguments,args, orargv. Soargs[0]will be the program, andargs[1]will be the 1st argument.(
argvis short for Argument Vector, it's called this because in C programming, arrays are commonly called "vectors")
Arguments are strings, that means they must contain text, and any section of text is a valid argument.
In shells like bash and cmd.exe on Windows, space is a syntax character; arguments are automatically separated by spaces. So if you want to pass an argument that CONTAINS spaces, you must wrap it in quotation marks to denote that it is a single string.
Consider this bash script file named myscript.sh:
#!/bin/bash
echo ""
echo "the currently running program is: $0"
echo "the first argument is: $1"
echo "the second argument is: $2"
Here are two examples where I ran this script in order to demonstrate
arguments:
$ ./myscript.sh i like eggs
the currently running program is: ./myscript.sh
the first argument is: i
the second argument is: like
$ ./myscript.sh "i like eggs"
the currently running program is: ./myscript.sh
the first argument is: i like eggs
the second argument is:
Standard Input Stream
Standard Input, often called stdin, is a stream of data that the process can read from. No encoding is specified, so it's a stream of arbitrary bytes. It could be text, or it could be something else.
stdin is usually used by multi-purpose programs like grep and sed which can process another program's output. This is colloquially called "piping".
Standard Output Stream
Standard Output, often called stdout, is a stream of data that the process can write to. stdout is raw "anything goes" bytes just like stdin.
stdout is commonly used for program output. By default, when running a program in an interactive shell, that program's standard output will be displayed in the shell.
The output does not have to be text and it does not have to be displayed to the screen; it could be raw binary data and it could be piped to another program or written to a file. For example on linux, the gzip program will output the compressed bytes directly.
For programs which do not have any direct output, stdout is commonly used for logging. Log messages may be written to either stdout, stderr, or both.
⚠️ NOTE: Many command line programs will behave differently when they detect that they are running inside an interactive shell, so they may format their output differently.
As an example, the
ls(list directory) command on linux will display files separated with spaces in interactive mode, and separated with newlines otherwise:~/example$ ls file1 file2 file3 ~/example$ echo "$(ls)" file1 file2 file3
Standard Error Stream
Standard Error, often called stderr, is a second stream of data that the process can write to. It's raw "anything goes" bytes just like stdout.
Unlike stdout, stderr should always output text and should be used exclusively for logging. By default, it is always displayed in the shell and never piped into another program's input.
File Descriptors (stdin, stdout, stderr continued)
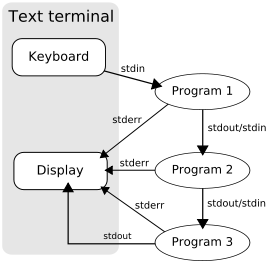
Sometimes we might want to change the shell's default "always display stderr, use stdout for piping" behavior. For example when we want to write the standard error stream to a log file, or we want to process it further before it's displayed.
In the bourne shell sh and its derivatives like bash and zsh, the stream-redirection operator > can be used to modify this behavior by specifying both the source and the destination as file descriptors.
Each process has its own numbered list of file descriptors, and by convention, the first three are always the standard io streams:
file descriptor 0: stdin
file descriptor 1: stdout
file descriptor 2: stderr
As a concrete example, some non-standard programs write thier help (usage instructions) to stderr, but we want to search for lines containing a specific string inside that output:
nmcli device help | grep wifi
This won't work because grep will only see the (empty) stdout from nmcli (Network Manager CLI). But if we redirect nmcli's stderr (file descriptor 2) into its stdout (file descriptor 1), then grep can filter the output for display:
nmcli device help 2>&1 | grep wifi
The & shell syntax is specifying that &1 is a destination file descriptor.
As another example, say we wanted to write the stdout and stderr streams to two separate files, for example, we have a web server that logs its status information and errors to stderr, while it writes its access log to stdout:
caddy run 2>/var/log/caddy-status.log >/var/log/caddy-access.log
Environment Variables
Environment variables are similar to program arguments, with two major differences:
- Instead of being a simple list of strings, environment variables are named; each variable has a name and a value, and you can't have two variables with the same name
- Environment variables are always inherited from the parent process unless otherwise specified
Some environment variable names like PATH and HOME are fairly standard across all operating systems, while others are specific to a single program.
⚠️ NOTE: If you run a program and then change an environment variable, your change will not affect any currently-running processes! Each process runs in its own environment, and that environment is copied from the parent when the process starts.
On Linux, you can run the env command to display all currently specified environment variables. On windows (PowerShell), you would run dir env:.
Here's a trimmed-down example from my computer:
$ env
SHELL=/bin/bash
DESKTOP_SESSION=ubuntu
HOME=/home/forest
USERNAME=forest
LANG=en_US.UTF-8
USER=forest
PATH=/home/forest/.local/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
ℹ️ NOTE: you can set or override an evironment variable for a process you launch in a shell by including the environment variable before the command.
MacOS/Linux:
MY_VAR=example mycommand
Windows:cmd /C "set MY_VAR=example && mycommand"
Working Directory
Every process has a "Working Directory", or a folder that it's running inside. If that process tries to read or write a file with a relative path, the path will be relative to the working directory. For example if the file path specified was myfile.txt, and the working directory was /Users/example/, then the file read or written would be /Users/example/myfile.txt.
The working directory is typically inherited from the parent process which spawned it, however the working directory can be changed if desired.
Run as User
By default, any new process will run as same user who was running the parent process. If you want to run a process as a different user, you will have to use a special tool that allows this.
- MacOS/Linux:
- BSD/Linux:
- Windows
Right Click → Run As Administrator...- runas
If you are using a background process manager like systemd or OpenRC on Linux, launchd on MacOS, or Windows Services, you'll be able to specify the user to run the process as inside your configuration file.
Typical Features of a Running Process
Process ID (PID)
The process ID is a unique integer ID number that the operating system assigns to each process.
You can access the list of processes along with thier IDs and other information with:
MacOS/Linux: ps (Processes) command
Windows: Task Manager / tasklist command
User ID (UID)
The user ID is a unique integer that the operating system uses to keep track of which user is running this process. There's also the EUID ("effective user id") for binaries like sudo which are configured to be able to change the user they are running as.
Group ID (GID)
Similar to User ID, but for group membership.
Currently Open Files (File Descriptors / File Handles)
The operating system keeps track of which files have been opened, and by which process. On Windows, you may not be able to delete a file or unmount a disk if a process is still accessing it.
ℹ️ NOTE: to list currently open files on your computer:
MacOS/Linux:
lsof(List Open Files) command
Windows: Sysinternals Process Explorer application or theopenfilescommand
Currently Open Sockets (Network Connections or Listening Servers)
Similar to files, the operating system also keeps track of network connections (sockets) to websites or services (local or on the internet) as well as listening sockets, aka servers, that each process has created.
Sockets may use either TCP (Transmission Control Protocol) or UDP (User Datagram Protocol). TCP guarantees that the connection is reliable and data is transmitted and recieved in proper order. When data cannot be transmitted or recieved, TCP will return a read error or write error. UDP offers higher efficiency and lower latency, but it doesn't guarantee proper ordering of transmitted data, and it can't provide feedback when transmission fails.
Besides TCP/UDP, there are two main types of sockets,
1. "Connected/Waiting" sockets aka "client" sockets
- Applications like web browsers create client sockets to connect to web servers and other types of servers on the internet (or to servers running on your computer or local network)
- "Client" sockets have two port numbers:
- source port
- a randomly generated large number like "41386"
- destination port
- the port number that the client connected to, for example port
80forhttpor port443forhttps
- the port number that the client connected to, for example port
- source port
2. "Listening" sockets aka "server" sockets
- Web servers themselves create listening sockets in order to "open a port" for incoming client connections
- "Server" sockets only have one port number, the listening port
ℹ️ NOTE: to list sockets on your computer:
Linux:
netstat(Network Statistics) command /ss(Socket Statistics) command
MacOS:lsof -i -P -n | grep LISTEN(list open files, then search for LISTEN)
Windows: Sysinternals TCPView or thenetstatcommand
Signals (SIGINT, SIGTERM, etc)
Processes can send signals to each-other. Typically this is used to shut other processes down when they are no longer wanted.
For example, say you ran a process in your shell, it's taking forever to complete, and you don't want it to run any more. You might press Ctrl + c on your keyboard, which will instruct your terminal to send a terminate signal or SIGTERM to the currently executing process.
If you've ever done this, you might already know that the Ctrl + c isn't guaranteed to end a process, some processes may ignore your request; perhaps they've crashed, they're in turn waiting for something else before they think they can exit(), etc.
In this case, you may escalate to kill -SIGKILL <PID> which instructs the operating system to remove the process immediately with no questions asked.
After a Process Exits
Exit Code
The exit code is an integer is commonly used to denote the reason why the program exited.
An exit code of 0 should always mean that the program succeeded or ran normally, while an exit code of 1 means that the program failed or crashed. Other numbers may be used and given specific meanings on a program-by-program basis.
If you ever see an exit code of -1, that may mean that the program never actually exited, perhaps it was SIGKILLed by the operating system instead.
ℹ️ NOTE: You can access the exit code of the previous command in the shell. It's
$?inbash(MacOS/Linux) and%ErrorLevel%incmd.exe(Windows)
If you notice any factual innacuracies in this article, please let me know or leave a comment below!
Comments