
Once upon a time, I worked for a company that loved SQL Server and normalized data. They loved normalization because it made their operational data store "alive", that is, no matter what data they changed using an UPDATE, INSERT or DELETE, all queries related to that data would instantly reflect the change.
Data Normalization
The practice of never replicating or caching data, and keeping data of similar type together in the same format. Each data point lives in one unique spot, and no two tables hold the same type of data. A commonly used strategy for relational databases like SQL Server.
Normalization makes a lot of sense from a custodial perspective. It works well with natural keys, and makes it easy to alter values without accidentally creating an inconsistency. There is only one place that an address can be stored in the system, so if I want to change someone's address, I just change that one record, and I'm done. If I see a bug where the address isn't updating, I don't have to worry that perhaps some address data is on the customer table or somewhere else. The database folks did their job, so all the address data is in the address table, no question.
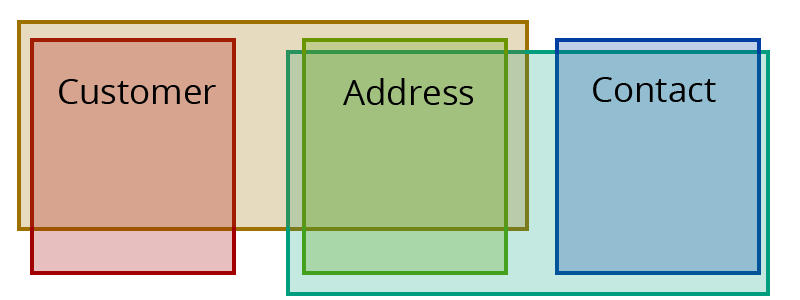
Normalized and de-normalized representation of the relationshipsCustomer AddressandContact Address.
Normalization in a traditional relational database works well at first. But at scale, there is a new problem. It's all live, all the time, and it's all tightly wound together. Any field can be changed by an application at any time, and the data is all interconnected. Given complex queries, it's hard for the database server to tell whether a given write would conflict with a given read. What is the server to do, then, if we demand consistent views of the data? Even if MVCC is used to prevent excessive locking, how do we reconcile a query that happened at the same time as a command? If something goes wrong with the query, how can we reproduce it, now that the database has changed?
Sometimes reads can be accelerated by adding indexes, but doing so slows down writes. Generally, either the writes will have to wait, or the reads will have to wait. In extreme cases this can result in one thing happening at a time while waiting for the disks to finish reading and writing blocks.
For today's applications, sometimes one thing at a time isn't fast enough. How can we optimize reads and increase availability? Asynchronously replicate the data to a dedicated view ala eventual consistency? Sure, but it comes with it's own host of problems. Maybe there is a better way?
Finally, because the data are densely connected, it is often hard to shard and scale horizontally. The performance demands for database software are ever-growing, and often the inability-to-shard will be the straw that broke the relational camel's back.
Don't Change That Data... Accrete it!
This post is all about re-thinking the way that we store data in our database. To get things started, here's a version-control parable.
There is no question that Git, Mercurial, and other distributed version control offerings are massively superior to SVN in the average use case. Likewise, I think most programmers would rather use version control than to simply store their source code folder on a shared network drive where others can edit it.
Imagine trying to debug code while someone else is editing it, or, imagine trying to co-ordinate a large scale software project hosted on SVN.
And yet, in the database arena, this is what we are doing today. Yes, storing application data and developing software are two different things, but hear me out.
From the application's perspective, the database is constantly-changing, wholly unpredictable, and usually slow. Sometimes our commands are rejected or appear to fail silently and we don't know why. We can't debug it directly, and we generally can't snapshot it, especially in production.
Let's imagine that when we have to add, update data or remove it from the database, we simply append the change to a log, like a Git commit, rather than updating-in-place, like saving a file. And while we are at it, let's also imagine that all changes to data are formatted as assertions and retractions of facts in a common format. In fact, this is exactly what Datomic does.
I've lifted most of the argument I'm making from a really clever guy named Rich Hickey. He created Clojure, a LISP-like functional language that runs on the JVM, and also created a totally novel database system called Datomic.

This radically changes our data store in a couple of ways.
First, the database is inherently cacheable forever, with no cache-coherence problems. If I tell you Sally's email address, then you don't know if she has changed it since you heard from me last. But if I tell you that Sally changed her email address at a certain point in time in the past, that is an immutable fact, guaranteed never to change. You can hold on to that fact for as long as you want, without causing any problems.
Second, we have the opportunity to ask questions about the past. I can ask to know all user's email addresses as of 12:00 noon today, or yesterday, or any other time, because time (transactionId) is part of every single one of my indexes. This feature can act as a keystone to support many other features like consistent reads and high availability. Unfortunately, the shared-network-drive-version-control doesn't support it, and the same goes for most databases.
Finally, instead of database clients, applications using Datomic will be database peers. The database can share its internal files full of immutable facts with "clients", or peers, rather than only sharing the results of queries. The queries will run on the peers themselves.
As a consequence of this, write and read responsibility can be completely separated. A single writer will be in charge of deciding which new facts are valid, while a message queue will transfer each new valid fact from the writer to any peers with matching subscriptions. With the use of probabilistic data structures like Bloom Filters, this single writer can support constraints on the data store without constantly reading values from it in order to decide if writes are ok. It can operate at extreme throughput like a stream processor, because 99.99% of the time, it does not need to trek to disk or wait for a network response in order to validate a transaction. It can just query the bloom filter and be done after a handful of instructions.
Good, concise explanation of bloom filters.
Datomic is built to easily support sharding and horizontal scaling. Facts all have the same schema, similar to RDF
(subject, predicate, object)triples, but with the addition oftransactionIdandisRetraction. After being validated, they are stored on multiple shard-able LSM indexes along those fields.Since all queries will come with a
transactionIdrange, peers will be able to know when they are "behind" and they can simply wait for their last known valid transaction to surpass that range before evaluating the query. This serves as a co-ordination method between nodes. Always consistent, eventually available.The best part is, peers own their own queries. If a peer wants to store a de-normalized view of the facts it subscribes to in MongoDB or somewhere else, there is nothing stopping it. It can even hook in to the same
transactionId-based coordination mechanism that the rest of the system uses. If something in that secondary view goes wrong, it can be destroyed and re-created from the history. This gives the data engineer the choice to cache and de-normalize without worrying as much about coherence. In my opinion, that is very powerful.Currently, as far as I know, Datomic is the only database of its kind, and it is relatively esoteric. However, I wouldn't be surprised to see more development in this area. It seems promising.
There is much, much more to learn about how Datomic works, and I don't think it is my responsibility to cover it here. Check out their Rationale for more information.
Comments