
This was a blog post I wrote for my employer's blog back when I was a "consultant".
In my last post I introduced the Disruptor pattern — a way of writing efficient, processor friendly code that is easy to parallelize, while maintaining developer sanity. This post is a case study of a real world application of this pattern in C#, along with a complete code example. Yes, names are changed, but this is a true story.
Say a client, CodeExampleCorp, the premier provider of todo lists, wants to move their Customer Relationship Management to the cloud. The boss has decided that all todo lists will be replicated to TodoListForce.com, allowing sales reps to better assist customers.
However, the QA engineers discovered that TodoListForce.com will slow to a crawl if we send it an unbounded number of requests. During peak hours, the number of todo list updates greatly exceeds that threshold.
We needed a way of batching many individual requests into larger chunks while transforming their format, and it needed to be fast, both in terms of latency and throughput. We decided to apply the disruptor to this stream processing problem because the requirements were constantly changing, and our initial solution using queues wasn't flexible enough to keep up. We knew it would help us build our process quickly and keep it agile.

Two groups of EventProcessors advancing along the ring buffer to the right and mutating events as they go. Each processor can run as a separate task or thread, however, they must never read or write to the same memory without being separated in the sequence.
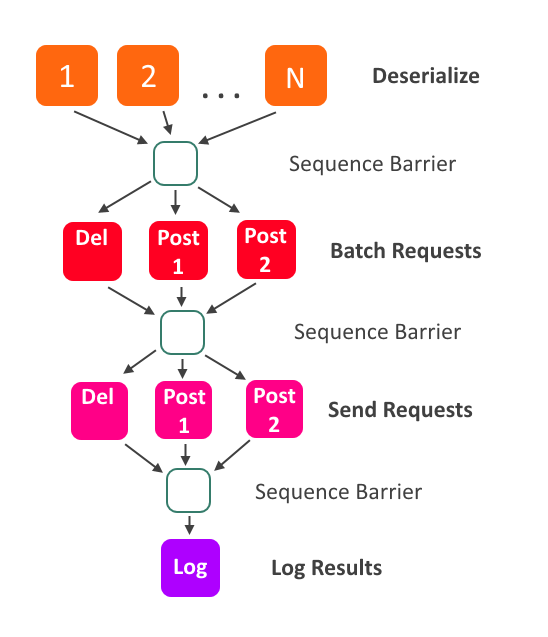
My code example shows a similar solution to the one we ended up with. Updates come in on the stream, and we have multiple processors working to deserialize them. After that, we split the updates up according to the request types that TodoListForce.com accepts, and batch them into larger requests. Finally, the requests are sent, and when finished, the results will be logged.
Each one of the colored boxes is an EventProcessor, and the arrows represent ordering. For example, all deserializers must advance past an Event before the RequestBuilders are allowed to process it.
|
The process dependency graph is built with a fluent syntax:
```javascript
var deserialize =
GetDeserializers(numberOfDeserializers);
var groupIntoRequests = disruptor.HandleEventsWith(deserialize) // Since the Request Senders are var sendRequests = disruptor.HandleEventsWith(sendRequests); var writeLog = GetFinalLoggingEventHandler(); disruptor.After(sendRequests) var configuredRingBuffer = disruptor.Start(); |
Comments