
In my previous post Pragmatic Path Towards Non-technical Users Owning Their Own Data I talked about how hard it is to host web applications on your own hardware, at home, or on a mobile device such as your phone.
I argued that most of the friction comes from cost of management... And most of the cost of management is linked to the network stack -- the user must find and maintain some way for inbound TCP traffic from the public internet to reach the device running their server application.
The problem is, it doesn't work by default on a home computer or smartphone. You have to change things to make it accept TCP connections, and it's done differently in each situation. In most situations, for example where your network is managed by someone else, you simply can't do it. That's why most small content creators use cloud services of one kind of another to host their content.

How 99% of web applications run today
In my previous post, I talked about a potential way to make it work. Run a TCP proxy in the cloud, connect your device to it via VPN, and then proxy inbound connections down the VPN tunnel to the device.
There are a couple problems with that solution, however. It inherently requires a centralized layer that someone has to pay for. All traffic must route through the cloud service. So if you want to do video or have lots of active users, cost will be prohibitive.
Back when I wrote that post, I also imagined the possibility that the browser could use WebRTC to connect to the server behind the NAT and bypass the cloud service. This would help ameliorate concerns about bandwidth.
2021 EDIT: this diagram represents how specialized p2p-enabled solutions like WebTorrent and PeerTube work.

A working, but non-standard solution
Unfortunately, there didn't seem to be any way to apply this kind of solution to ANY arbitrarty web app. The closest one could get would be to write a new JavaScript framework which handles this by monkey-patching / polyfilling browser APIs and monitoring changes to the DOM. It would also need a server component, and prospects for easy integration with existing apps looked grim. It seemed to be a non-starter.
But now, enter ServiceWorker.

This totally changes everything.
ServiceWorker enables a backwards compatible standards based solution
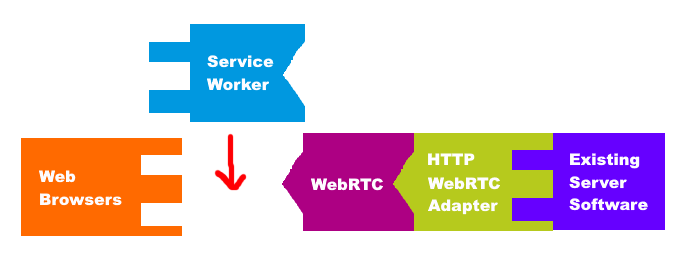
The ServiceWorker API allows web developers to register a JavaScript-based HTTP request interceptor with the browser. It is associated to an Origin, and from that point on any request the browser makes to something under that Origin will pass through ServiceWorker before being sent. It's meant to replace the HTML 5 Application Cache and provide a more powerful, flexible, and reliable interface for offline content. But most importantly, it allows us to easily execute any JavaScript code to handle any external call the browser would make (on the same origin), not just XMLHTTPRequests!!
So, we can modify the previous TCP-proxy-based design to only use the TCP proxy for the initial (non-cached) connection from a device. After that, HTTP requests will be intercepted by the ServiceWorker and sent down a WebRTC-based tunnel. This would dramatically decrease the bandwidth required for the untrusted cloud server, potentially lowering it to the point where this service could be provided for FREE.
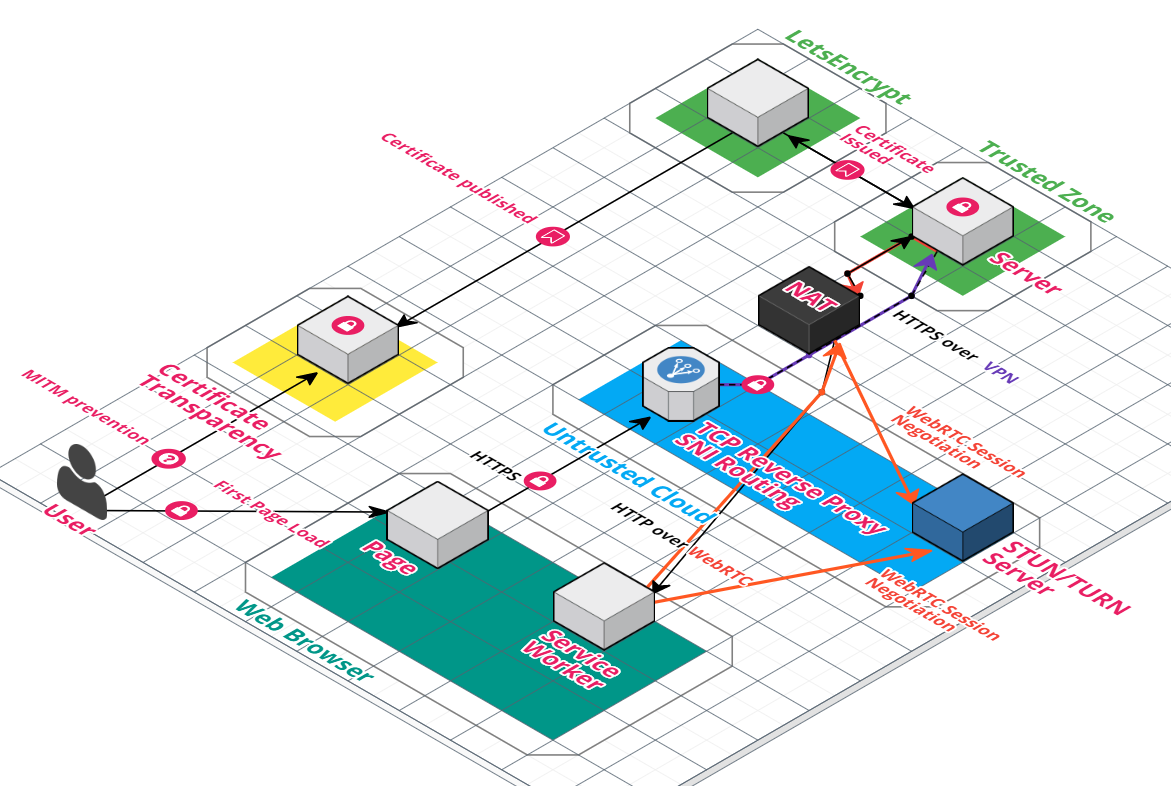
The best part is, it could be transparent to a client/server web application that is running in this environment. Potentially ANY HTTP-based web application could run here without modification. Simply run a reverse proxy in front of the initial request that modifies the response body, injecting a <script> tag for the service worker. That is HUGE in terms of the potential impact this technology could have. The only caveat being that I may not be able to prevent the ServiceWorker which gets injected by the squid server from conflicting with any pre-existing serviceworker that the web application may already use. But luckily most web applications, especially old ones, don't need and don't use ServiceWorkers.
Anyway, needless to say I am excited about this and I might try to build a proof of concept for it sometime soon.
EDIT: June 2020: I have created the repository for this project, but it will probably be a long time before I start working on the actual http revserse proxy, serviceworker, and webRTC bits.
EDIT: August 2022: I wrote a giant readme full of hype and started working on prototypes for this, but I don't have anything close to a demo yet.
Comments