
I don't have a statistic, but I assume that the vast majority of the applications and content that the average user interacts with these days goes through a web browser at some point.
If your app doesn't have a URL, who's going to use it?
The question haunts anyone who wants to build new peer-to-peer applications and networks.
Beyond the ability to type in mystuff.newcoolthing.com and receive instant HTTP-based gratification, users expect a lot from web applications these days:
- 100% functionality in the app/browser within milliseconds
- Gmail, Youtube, Google Docs, Facebook, Twitter, etc
- Mobile Friendly
- High Availability
- 99.9% Uptime
- Worst case first impression load time less than 3 seconds.
- Green lock icon in URL bar
If your app doesn't fit those criteria, it is likely to be left in the dust. So how can we build peer-to-peer apps in such an environment? Or apps that allow users to own their own data?
In recent history, the answer has been that you don't. Besides a few ancient and highly specialized peer-to-peer networks like BitTorrent, almost all apps are cloud based and operate under centralized authority by necessity. While some people (and some shareholders) might consider that total authority and exclusive ownership of all user data to be a great feature of "the cloud", I consider it a bug.
Let's play Web Mad Libs...
A user types . into their web browser. The web browser sends an HTTP GET request. The implementation asks the system to resolve ., and ultimately receives some public internet IPv4 address --.--.--.-- from the user's ISP's domain name system. The browser talks HTTP with the server at --.--.--.--. That server may proxy and/or route the HTTP connection to (in the network) at the protocol level. When the connection reaches , it will be redirected via the HTTP protocol to HTTP2/HTTPS. The process will repeat, this time with the TLS negotiation occurring/terminating at . All of the application's code and data is delivered to the browser over the HTTP2/HTTPS connection, the app s in the browser, and away we go. Oh, and don't forget: the user's login credentials are always transmitted and managed via email and SMTP.
Even with the rigid restrictions imposed by established infrastructure and user expectations, we might be able to leverage open source tools and cloud service providers to sneak user autonomy, data ownership, and decentralization into this framework.
But first, consider the:
History of price deflation to zero in Web Technology
- Price of web server software
- 1991: $0
- Price of a DNS entry
- 2003 (and probably earlier): $0
- Price of access to a decentralized, global, immutable, and extremely secure ledger/database
- 2009: $0
- Price of a server with 99.9% uptime
- Price of a TLS certificate
- 2015: $0
I always liked the idea of hosting my own stuff -- providing a URL to myself and to the world under my own power, under which I can put whatever I want. I don't even have to pay for it, besides the energy used and $1 a month for a domain name. But the devil is in the details. What happens when your internet service provider has an outage in your area? What happens when someone trips over the modem in your living room? What happens when the power goes out, or when you move? The TLS certificate expires? The server runs out of disk space or powers off unexpectedly?
These days, people don't bother to self-host anything because it's a nightmare to manage, not because it's expensive. There are so many things that can go wrong, and it's so much easier to just fork over all your data to the free cloud services. Or if you are a business, maybe you shell out thousands per month for an Enterprise Cloud Services Account with the expectation that, while your counterparty does in fact own all of your data and systems, they won't touch them because betraying your trust would risk thier revenue.
But with all of the free services, automation tools, and great FLOSS software that is around these days, I think self hosted apps could get a second chance. The trick is to automate the complex, manual parts into a platform that's just a few clicks away from potential users.
Here's my proposed architecture for highly available web applications, owned by their users:
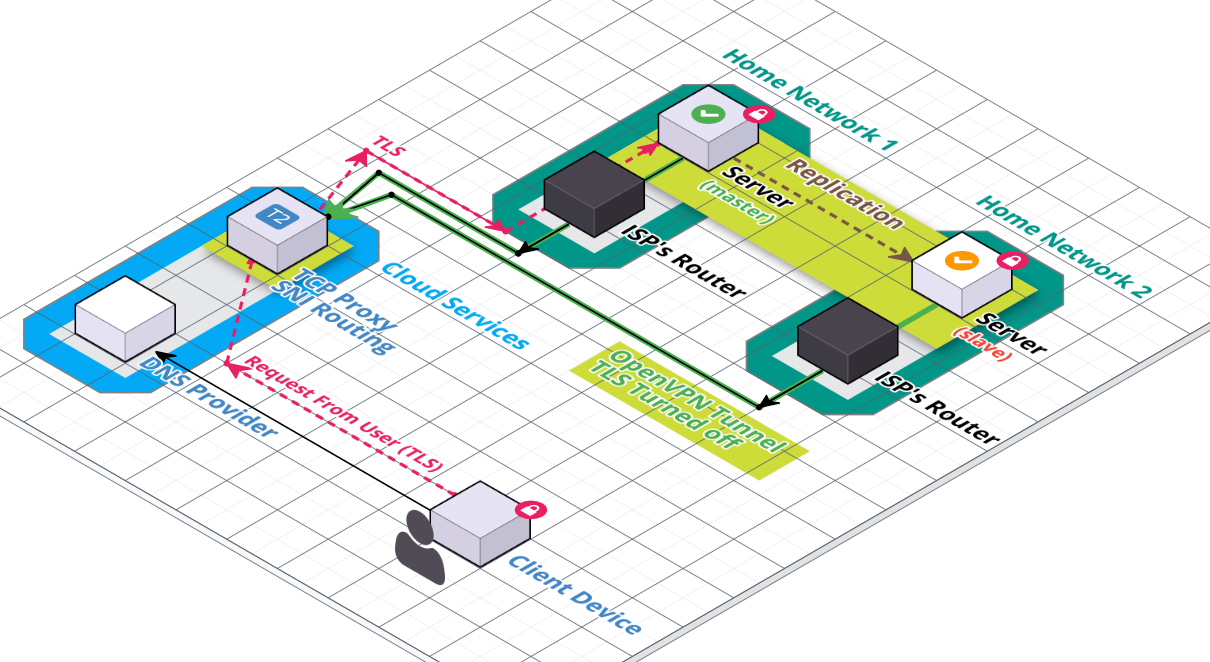
There are a few key features of this architecture that I would like to point out:
- If one app server goes down, the service stays up and chances are no data is lost.
- The haproxy running in the cloud runs an OpenVPN server which allows the app server to tunnel through NATs and firewalls.
- App servers are plug and play. Doesn't require the user to own their router and configure port forwarding on it. Supports public wifi and cellular networks.
- Cloud instance doesn't need to be powerful, all it does is pipe network traffic. OpenVPN encryption could be turned off.
- Using haproxy with Server Name Indication (SNI) Routing this could be a multi-tenant service.
- It still couldn't read the traffic even if it wanted to.
- Actually it could, but it would require the hacker/cloud provider to reroute traffic, generate a new TLS certificate, and start MITM'ing, which they should be unable to hide from the user/tenant, as long as the software has a way to check for it.
- This would be similar to companies installing bad CA certs on employee machines and MITM'ing, but the unauthorized cert lives on the server.
- Ideally, the apps and the infrastructure that runs them would be separated
- Users using a given pair of servers must trust the admin running them.
- Apps are walled off from each-other by containerization
- Apps must trust the environment they run in, but not necessarily vice-versa
- It's possible that the haproxy in the cloud would only be required for bootstrapping the app.
- The app servers could have multiple networks
- One going through the VPN for accepting requests from the internet and establishing initial TLS.
- One tunneled directly, to reduce load on the cloud instance (WebRTC? clever NAT punchthrough?).
- The app servers could have multiple networks
As a matter of fact, this is exactly what I plan to move towards for sequentialread.com in the future. I already have an instance of openvpn and haproxy running in TCP mode on AWS, serving the page you are reading right now... All I need next is a good way to set up my apps in clustered mode with replication, and a secure management tool to administer the whole system from one place.
Of course, that would require a lot of work, so it won't be done any time soon. I've been thinking about this stuff for a while, and I'm sure I'll continue to revise my thoughts as I try things out.
Note: the VPN, HAProxy, SNI routing, etc I wrote about in this article has since been replaced by my threshold project.
Comments