
In my last post, I wrote a about how I'm changing direction away from my "trustless cloud-based gateway to make self-hosting easier" project called greenhouse. I also wrote little bit about where I want to go with my software projects in the future. In this post, I'm going to expand further on that. In fact, I'm writing this now so that I can help myself organize my thoughts and clarify my own ideas.
Last time I said that I wanted to produce a piece of software in which two server admins' servers can "federate" with each-other. Another 3rd friend who doesn't run thier own server can have an account on these two servers.
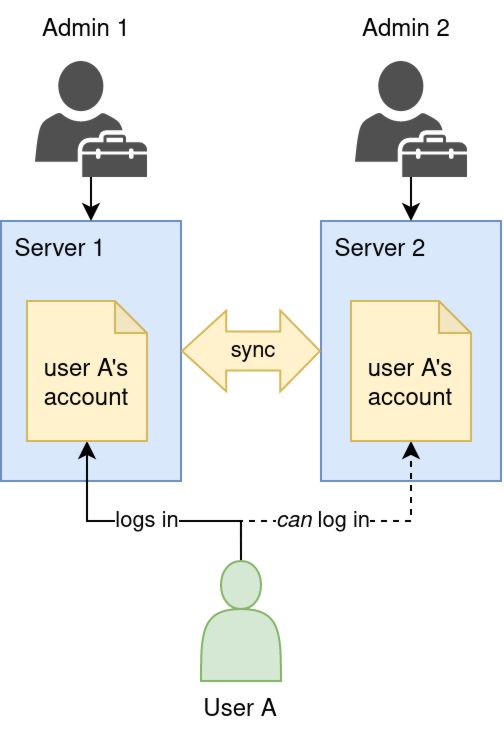
If the server on which the account was originally registered gets powered off or lost in a fire, the friend can still log in and use their account like normal on the one remaining server.
However, I think when I said "federates", it may have been a bit of a misnomer, perhaps it might be more accurate to say that the two servers form a cluster with each-other and that they replicate the data.
But wait a minute. Cluster? Really? What is this, a "cloud scale" enterprise solution? "Cluster" makes it sound like a supercomputer. I thought this was about something that folks run at home, ya know, livingroom servers?
But before we get into that, its time I define some of the terms I'm throwing around and give a brief refresher on what the heck these things actually are, how they work, why they exist, and most importantly, how they tend to fail.
Federation
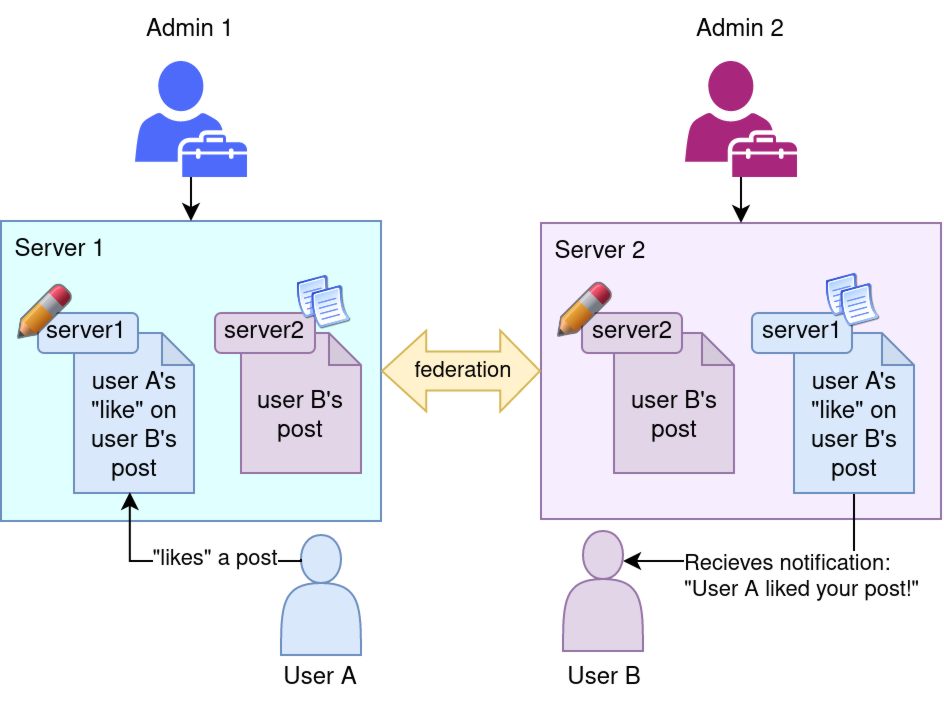
Federation has become a bit of a buzzword among the FLOSS and self-hosting communities within the past few years. Federated systems like matrix are beginning to provide (in my opinion) the first real viable alternative to centralized social media platforms. Federated social media protocol standards like ActivityPub connect users not just on different server instances, but between different types of server software.
For example, if you post a photo on your PixelFed account, my GotoSocial account can "like" it and someone else's Mastodon account can leave a comment. Such is the nature of the emergent social network dubbed "The Fediverse".
 Writable
Writable Read-only Replica
Read-only Replica
ℹ️ Note: Each account on this style of federated platform is intrinsically linked to its "homeserver", the server on which the account was created. Federation partners are free to store copies of accounts and activity records from other servers, but in general they're not allowed to create or update anything that "belongs" to another server.
The homeserver concept is deeply embedded in the design of the ActivityPub protocol; there's no way around it. Every single ActivityPub message contains an
idproperty which must be a URL identifying the dial-able address of the server who is considered the authority for that information.{ "@context":"https://www.w3.org/ns/activitystreams", "id":"https://friend.camp/users/darius/outbox", "type":"OrderedCollection", ...
These new "grassroots" distributed platforms are succeeding because they have managed to generate/harness network effects: They're good enough at forming and maintaining connections between servers that even though there may be hundreds of different people and organizations operating servers, having one account on one server means you can theoretically "reach" the entire network.
At the same time, federation is opt-in and fine-grained enough that new servers joining in aren't instantly swamped by traffic from the entire network. If I operate a federated social media server and invite 100 users to join, they may eventually "follow" thousands of other accounts on hundreds of other servers.
That might sound like a lot for my poor server to process! But it's nothing compared to the millions and millions of fediverse accounts that exist. Computers are really fast, and for them, hundreds or thousands of things is a piece of cake.
💡 Key Idea: Each fediverse server is operated by a different administrator, and may play by different rules. Servers can ban eachother, limit eachother's federation based on arbitrary criteria, etc. They can have software bugs and be incompatible with each-other, the sky is the limit. Each server admin has complete control over what happens on thier server.
Clustering
"Cluster" usually refers to software that was designed to run on multiple computers in order to harness thier aggregate computational power and data bandwidth. This practice is often called "scaling horizontally", and it is desirable from a business perspective because, in simple terms, it's a lot cheaper to buy & maintain a bunch of small computers than it is to buy & maintain one huge computer. Plus, if we play our cards right the army of smaller computers can be much more reliable, since it can avoid single points of failure.
- Writable
- Read-only Replica
As you can see, this one is a bit of a doozy.
ℹ️ Note: In this example, there is only one administrator. Every single cluster system I have ever encountered is like this: Intended to be deployed entirely by one organization, entirely under one umbrella, always within a single datacenter LAN.
In this case, there is no self-determination angle, clusters as we know them were borne primarily from economic factors that only influence large scale software and web service companies.
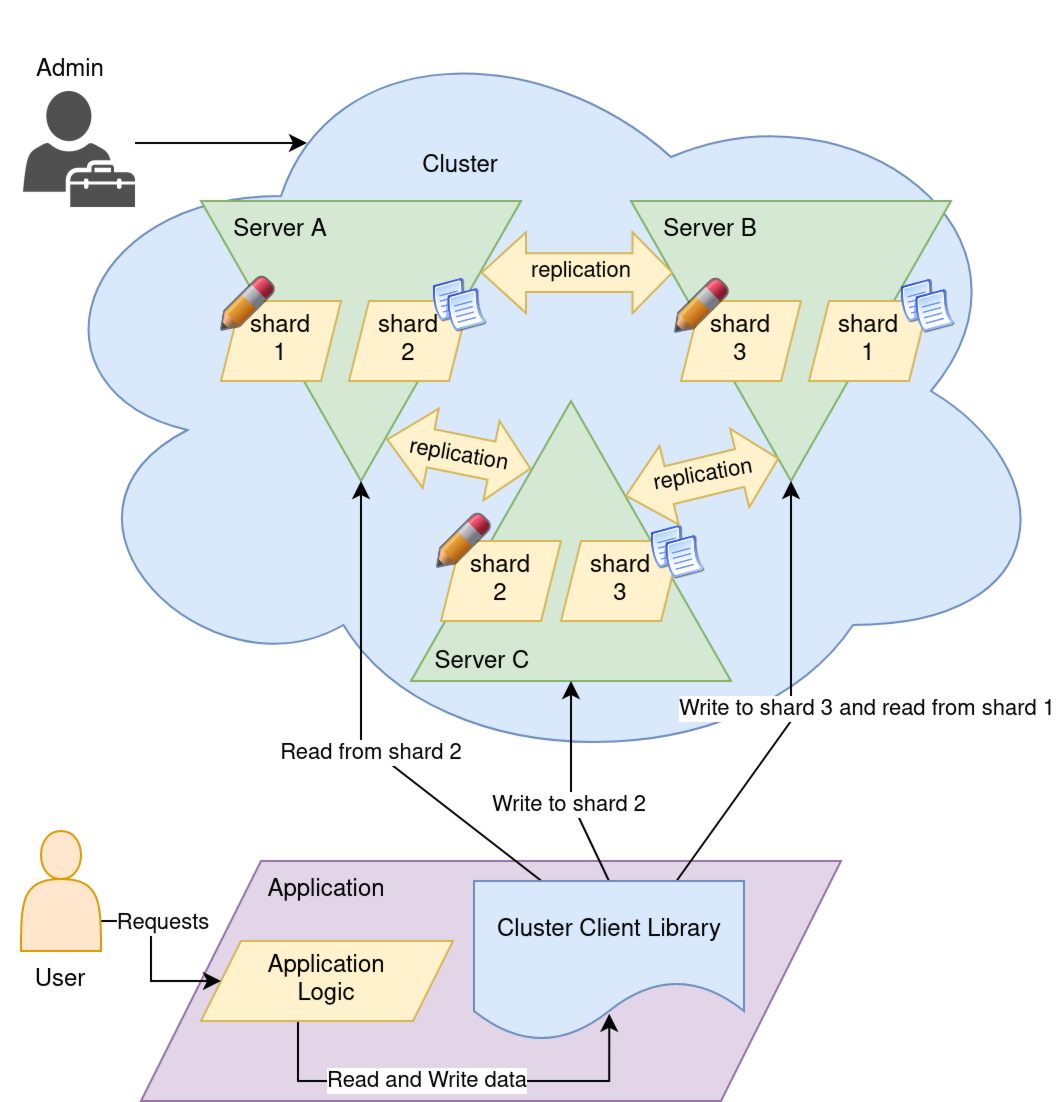
- There are three servers,
A,B, andC- Three is often the minimum number of servers for a cluster to reach its full potential.
- Large clusters may include hundreds of servers.
- The data is split into three "shards",
1,2, and3.
-
Note that each shard is replicated to two nodes.
- This guarantees that if one node goes down, the system continues operating.
- As long as the replication is working, even if the node who is currently the writer for a given shard goes down, its replication partner node can be instantly promoted to be the new writer.
- The cluster client library may be able to predict which shards it needs for a given query and only contact nodes owning those shards.
- If it can't, that's fine too. Whichever node is contacted by the client can forward the request to the appropriate server(s).
- For example in the above diagram, if the client asked
Server Bto write toshard 1,Server Bwould simply proxy the request toServer A, becauseServer Aholds the "primary" ofshard 1, that is,Server Ais the designated single writer forshard 1.
🤔 Remember how the ActivityPub federation protocol put a single
idproperty on everything, and thatidis a URL which specifies the dial-able location of the authoritative server for this info?{ "@context":"https://www.w3.org/ns/activitystreams", "id":"https://friend.camp/users/darius/outbox", "type":"OrderedCollection", ...
Lets try to find a comparable example for Apache Kafka. How does kafka handle this?
Apologies for the incoming wall of information; please bear with me through it. Or if you're not feelin it, just skip this part, most of it is details that don't matter for the overall story anyways.

A Kafka cluster is composed of one or more servers called Brokers. A Kafka cluster also has one or more Topics. You can think of a Topic as following the spirit of a Table in a relational SQL database. Topics are broken up into multiple partitions, where each partition represents some arbitrary slice of the data inside the topic. Not as a slice of time, but as a slice of the entire history of the topic.
In the following screenshot from the cute kafka explainer https://www.gentlydownthe.stream, a kafka topic is represented as a river:

Each partition is just a sequence of messages, and each message in a partition is identified by its offset within the sequence. So the first message in the partition would be at offset 0 and the 100th message would be at offset 99. The offset can only increase, never decrease, as the partition is an append-only log.

This part of kafka utilizes a separate consensus cluster software called ZooKeeper. Yes, that disturbingly proportioned little cartoon man holding a poop shovel really is the official logo 😬
So at the end of the day, the full "address" of a message in kafka might look something like <topic>/<partition>/<offset>. (Although, you would never it see written out as a path like that.) Anyways, when it comes time to grab a single message like that, how would Kafka do it? There's no directly dial-able address here like there is in ActivityPub.
Why, it uses the Broker Index and Topic Index, of course 🤪!
/brokers/ids/[0...N] --> { "host":...,"port":... }
/brokers/topics/[topic]/partitions/[0...N]/state --> {
"leader":...,
"isr":[...]
}
So first we look up the partition's current state. The leader will be the broker ID of the broker who has been assigned as the single writer for that topic partition.
The isr stands for "In Sync Replicas" (No, unfortunately its not an nsync cover band 😥)
The "In Sync Replicas" is a list of broker IDs representing all brokers who are currently replicating the partition from the leader in real time.
From there, we simply look up the hostname and port of the broker in the broker index by id. In this way, we can connect to any of the brokers we found and issue a fetch request to grab messages starting from a specific offset. Or, if we want to issue a publish request to append a new message to the end of the partition, we have to specifically use the leader broker.
💡 Key Idea: The topics, partitions, and messages don't know or care which broker they are on, how many brokers there are, etc. This is a separation of the logical data organization scheme from the underlying hardware configuration.
The cluster's internal protocols handle the real-time tracking of where everything is, and that internal metadata is kept separate from the data that the system is storing/processing.
This kind of separation exists in every piece of cluster software that I've seen. The replication we see in the logical layout provides "high avaliability", while the separation between the logical layout and the physical reality of the dial-able hardware helps with "fault tolerance". It's much easier to recover from a node failure if it doesn't require millions of URLs embedded in the data to be updated.
Put together, these two properties give clusters superpowers that normal single-computer programs can only dream of.
- A computer can catch on fire and explode without causing a noticeable impact to the system.
- A destroyed node can be replaced while the system is running, again, no noticable impact from a client's perspective.
- The system can be upgraded to a new version, including breaking changes, while it's running. You don't have to turn it off to upgrade it.
- The software's performance isn't limited as much by the hardware it runs on because its design spreads load out evenly among multiple computers.
- Often times if you need the cluster to do more work or do the work faster, you can simply add another node.
Of course, I can't talk about clusters without mentioning the Big Important One that everyone is excited about: ☸️ Kubernetes.
Mostly up to this point, I have been talking about storage-related cluster software. ElasticSearch, Kafka, Cassandra. But Kubernetes is different, it's all about computation, running lots of programs instead of storing data.
I don't dislike Kubernetes, in fact on the surface level it seems like it could be an option for any project that aims to configure & run multiple programs spread across multiple computers.
But about three or four years ago I made an explicit decision not to try to use it for home-server related projects. I think it's simply not the appropriate technology.
Why?

Ultimately it came down to the network. As far as I know, from design, development, testing, and into production, the core of the Kubernetes cluster system, the "etcd" / "control plane" components were always intended to live on the same LAN. Whether the control plane nodes could talk to each-other directly wasn't in question, it was simply assumed that they always could. Not only that, it was also assumed they could talk to eachother with super low latency.
But in the home server environment, it just ain't so. Sure, you could run multiple servers in the same house. That would work fine, but it isn't going to increase the reliability of your services very much. Most outages will be caused by things like ISP outages, power outages, the cat knocks over the router and unplugs it, you lose your house in a natural disaster or move the server to a different house in a different city, etc.
Really, if we're trying to make a home server "cluster", we're gonna need multiple people's homes as well as multiple servers. But therein lies the problem: unlike the cloud and datacenter machines, these home servers are living in what an aquaintance of mine calls "NAT Jail." They can't be directly contacted from outside unless the self-hoster performs some port forwarding configuration on thier router first.

And even then, those home IP address are liable to change somewhat regularly. Many self-hosters may not even be able to configure port forwarding if they wanted to ☹️. It's all situational. So if I wanted to use Kubernetes in this context, it would probably require a VPN to be set up across all the nodes ahead of time. That's already enough of a red flag for me to call it quits; I want my multi-server solution to help me network my servers together from behind NATs and firewalls, not to demand that I have already done that part perfectly before I can turn it on.
I could definitely use Kubernetes as a single-node cluster, as many people do. In fact, someone is already marketing a self-hosting focused product around it. But if I was going to do that, why not just use docker-compose? Or use single-node docker swarm like co-op cloud does?
To be fair, I haven't kept up with the developement of various different lightweight Kubernetes distributions like k3s, and who knows, maybe in the year 2022 there is now a kubernetes distribution designed specifically for people who run servers in the mountains with solar panels and handmade radio antennas 😛
EDIT: after sharing a draft of this post on the cyberia.club matrix chat, my friend Winterhuman from the very cool IPNS-Link project pointed me to exactly the thing I was missing:

 forest (he/him) Just read [your post] and thought you'd be interested in https://github.com/c3os-io/c3os, it's a Kubernetes distro, but, it uses Libp2p to escape the "NAT Jail" you talked about
forest (he/him) Just read [your post] and thought you'd be interested in https://github.com/c3os-io/c3os, it's a Kubernetes distro, but, it uses Libp2p to escape the "NAT Jail" you talked about
heh, I knew it had to exist
very cool, although I think I would prefer something that has an installer instead of being a linux image build script. Installer is more portable, the ARM hardware requires different images for every single different board 🤮
and I still have reservations about kubernetes and to a lesser extent VPNs
but the parts it is composed of / overall approach is super interesting.
You could do something similar, minus the config and the Libp2p stuff being built-in, by using https://github.com/hyprspace/hyprspace to create a VPN first (it can adapt to IP changes) and then layer stuff on top of it
I still have to figure out how I wanna structure it
I've never used a VPN with docker before so that would be my 1st step.
At least for now, I stand by my decision to skip the Kubernetes for self-hosting. At the end of the day this c3os thing is still just an easier way to set up a VPN as a pre-req, and Kubernetes still has a lot of issues with complexity and usability in my opinion.
Honorable Mention: P2P Networks
But Forest,
You ask,
Distributed Computing? Decentralization? Self Determination? My friend, you are describing a peer-to-peer network. You should just use ipfs and all of your problems will be solved.
Well, dear reader, if I caught you thinking this, don't worry. I get it. I love P2P as much as the next guy; I've dreamed up a hairbrained scheme to rebuild twitch.tv as a peer to peer network that runs in the web browser, hacked on WebTorrent on my livestream, and I even wrote a passionate plea to breathe life into Namecoin.
Ok, wow Forest, if you love P2P so much why don't you marry it?
The TL;DR is that the web browsers everyone uses still do not support IPFS in 2022 and I'm unsure if they ever will. I'm not holding my breath.
I do believe in transformative P2P applications that are worth downloading a client app for. I've seen two so far in my lifetime:
- BitTorrent
- cryptocurrency
But I think anything to do with media or publishing is still going to have to at least support the web browser, either with oldskool HTTP or with P2P support directly in the browser. Not a special browser like Tor Browser, but at least Firefox, and probably Chrome too.
IMO, things like ZeroNet, Beaker Browser and GNUnet are interesting and compelling, but with no mainstream web-browser adoption anywhere on the horizon, they're nothing more than toys or prototypes with no possibility of generating enough network effect to get going.
It's like I wrote 6 years ago:
WebTorrent is a perfect example of P2P support in the browser. If you haven't heard of it before, I highly recommend checking out the demo on thier front page: https://webtorrent.io/
In fact, it's so cool, I'll include a screenshot of it here:
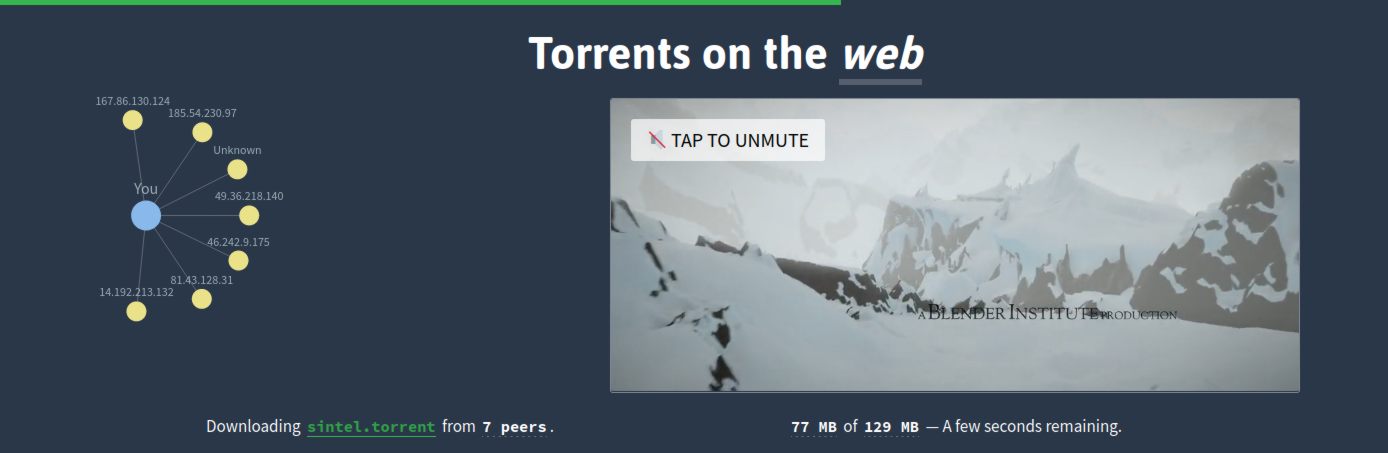
In case you aren't sure what's going on here, it really is torrenting a video file in real time in your web-browser. Those yellow dots on the left are the "torrent swarm", the other people accessing the demo at the same time as you. They are all sharing chunks of the video file to each-other to accelerate the download. In fact, unlike a traditional HTTP file server, the more people who attempt to torrent this file at once, the FASTER the download will go for everyone.
It's amazing to me that software like this is already mature and has been doing this in the web browser for years, and it's now powering potentially useful apps like PeerTube. I think there's a lot more untapped potential for these kind of peer-to-peer enabled web apps.
However, we can never lose ourselves in the hype. Remember that this is only ever going to work on your mom or dad's computer because someone is running a traditional HTTP server to provide them with the "backwards compatible" web application and JavaScript to make this happen.
If you want to harness this kind of power yourself, if you want to send someone a link to your own version of this, you're probably going to have to set up that HTTP server too.
I think we're going to be using HTTP and TLS for many more years; in my opinion it makes sense to start from there.
I'm still searching for a way for folks to set up thier own publicly dialable HTTP servers hosted at home or within thier own community. Ideally, without nearly tearing thier hair out in frustration in the process.
Bro you said "brief refresher," wtf
Ok, that exposition may have gotten a little out of hand. These are complex topics:
- Federated Social Media Protocols/Platforms
- Storage and Compute Cluster Applications
- Also, Peer-to-Peer networks apparently?
And they're all so close to my heart, filled with personal stories, feelings, funny anecdotes, etc.
Ok ok, I promised I would cover:
how they work, why they exist, and most importantly, how they tend to fail.
I believe I have covered the first two fairly well. So now it's time for...
most importantly, how they tend to fail
I used to work on distributed systems a lot at a my old job. I did a lot of work upgrading Kafka and Cassandra clusters while they were running & spent a lot of time monitoring the health of the clusters, learning about what can go wrong with them and debugging issues as they came up.
Cluster applications are much more complex, so they're harder to interact with. They almost always require special client software or client libraries to interact with. Sometimes these clients feel like they're missing some important features, but doing anything with the cluster "by hand" without the client can be scary or prohibitively difficult.
They're also very hard to debug. When you get off the beaten path, thier user-interfaces, especially when it comes to error handling, range from "very poor" to "non-existant". It was so bad. I remember having to SIGKILL (run kill -9) on stuck kafka broker processes quite often. Not a comfortable feeling on a production system. We never lost any data tho!
All in all, I think that clusters are easily misunderstood and almost always difficult to work with. There's just so much going on with them, especially complex clusters like Kubernetes, it can be overwhelming.
Part of this is because of the complexity, but I think it's also because contemporary demands for clusters were almost exclusively about more storage, more bandwidth, more stuff. These clusters were only ever intended to be operated by highly trained mega-nerds in a professional setting; they could get away with little to no interface for the operators. Instead, all the development effort went into optimizations and new features.
The environments where these clusters run and the jobs they fulfil are some of the most demanding ever known to computing. It's not surprising to me that they're difficult to use.
💢 Clusters fail before they get started. People like me refuse to use them because they are simply too big and difficult, the requirements are too high and inflexible and there's relatively little payoff.
In the homebrew realm, clusters fail specifically because they've all been designed to run on a shared LAN. In thier current implementations, the individual cluster nodes can't/shouldn't be spread to multiple different localities.
Whoever has power and internet at home that's reliable enough to justify deploying a whole cluster on... Well, they must live in a datacenter, so they're irrelevant in this case 😆
Federated social media services, on the otherhand ARE often designed to be easy to self-host, sometimes even including how-to guides for hosting at home. They're fairly easy to get started with, but sometimes struggle to achieve longevity.
Many people have commented on this phenomenon at length. Personally, I'm a fan of Darius Kazemi's discussion of some of the issues at play on his how-to guide https://runyourown.social/.
Some highlights from my memory of that guide:
- Administering one of these sites is a significant & continuous burden.
- It's a big responsibilty: if you stop maintaining it, everyone who has been depending on you will at best have to go through a migration process, and at worst lose their account and everything that was attached to it.
- You'll probably want to maintain a federation block list to keep various kinds of 4chan-esque "nasties" off of your server.
- You probably want to limit the number of users; servers that have grown out of control invariably run into problems.
- Often these problems are more social than technical: There will be disputes. There will be situations where you have to make moderation decisions which will alienate some of your users. You can't please everybody.
- Allowing anyone to register an account at any time is probably a recipie for disaster for similar reasons.
The way I see it, the average Fedi instance is somewhere in between:
- a personal experiment that can always be shut down
and
- a service that many people rely on & can't be allowed to fail
It's an awkward in-between for sure, and I think this is the crux of the issue with the federation concept as it's implemented in the Fediverse.
In order to preserve the autonomy of each fedi admin, all of the user data under thier care is intrinsically linked to the domain name of the server they operate. It may be possible for one admin to pass the torch to another person, but I suspect this rarely happens in practice.
Usually when an admin loses interest in maintaining something like this, it'll happen without warning, and by the time it becomes apparent, it might already be too late to try to transfer ownership. Life happens. Sometimes circumstances change and folks won't have the spare time for this kinda thing. That has to be ok. Technology is supposed to work for US, not the other way around.
💢 Instances of Federated network software fail because they place a constant burden of maintenance on (usually) a single administrator.
These instances are often designed to be easy to set up, but as soon as folks start using them, they can become entrenched and both difficult to maintain as well as difficult to transfer to someone else. For example, it's not enough to transfer a backup of the server's data or the physical server itself, one would also have to transfer ownership of the domain name.
It can turn into a quagmire where the users stand to lose a lot and the admin doesn't have any easy way out.
Cool story. But what is this all about?
I created greenhouse because I was frustrated with how difficult the network configuration part of self-hosting can be. Specifically, I was frustrated by the lack of solutions that always work no matter what.
I thought I saw a need: All of these self-hosted software setup guides are super easy and simple until you get to the part about NATs, routers, port forwarding, DNS, dynamic DNS, etc. Then everything goes off the rails into seemingly endless tangents and what-ifs.
I've written on this before: Shells are well standardized. Linux is fairly standardized. The web protocols like TCP, TLS, and HTTP are incredibly well standardized. But every home network is different, there's no single way to configure the network for a server.
Greenhouse was an attempt to allow the self-hoster to flip the table and refuse to configure the home network at all. It was Infrastructure as a Service that outsources the DNS configuration and TCP listener into an easy-to-use public-cloud-based service while keeping the TLS (encryption stuff) on the self-hosted server.
I believe that greenhouse failed because on its own, it failed to address a widespread need. As I explained in my last post, greenhouse catered to self-hosting fundamentalists, but at the same time, it IS a 3rd party service, the bane of every self-hosting fundamentalist's existence.

So I ended up trying to rethink the whole thing, rethink my whole approach.
I was inspired by the way that the fediverse had seemed to address two extremely common needs at once.
- Convenience. Just sign up for an account; don't have to run your own server
- A sense of data custody and belonging within a tight-knit community
Even better, unlike greenhouse, this time the venn diagram has a huge overlap, it's practically a circle.

In fact, I think the same venn diagram can be generalized to talk about huge swaths of the internet today. It's funny to me that everyone wants a server but no-one wants to run one. But I think it's all too true.

The list of internet usecases which could conceivably fall into this category goes on and on.
It reminds me of the children's story The Little Red Hen.

Except this time she's baking digital bread with near-zero marginal costs, so even if the hen and her chicks eat first, there should still be enough left at the end for the the Pig, the Duck, the Cat, and everyone else in the pasture.
But there's just one problem with this little "online era" adaptation of The Little Red Hen. If there's one thing I learned in my career as a digital bread factory technician (and my subsequent mini-retirement as a trappist digital bread monk), it's that when it comes to the best of breads that bring the boys to the yard, nobody can bake em alone.
That is, popular web technology, especially when we consider it as the entire stack all the way from the server's power supply to the router, the operating system, processes, protocols, html, images, text, usability, design appeal, accessibility, client compatibility and everything else, its simply way too much for one person to carry.
I have been trying to carry all of it myself in my work on greenhouse and my other personal projects that never saw the light of day, and it's been hard. I haven't seen any success yet.
But I'm trying to stay positive. I love the internet because no matter how uniquely impossible your personal struggles may seem, there's probably a niche community out there somewhere where you can commiserate or find some kind of solace. No matter how obscure your problem, you can always find someone else who has the same problem. The internet is amazing for forming communities and meeting new people who you have something in common with.
And in those communities, through collaborating with my friends, I have seen some successes. The graph of greenhouse users and activity went down and to the right. But another project that I developed with my friend j3s, capsul.org, is going up and to the right, and it has been for over two years now!
capsul.org revenue - $/mo all-time avg
As happy as I am to see capsul succeed, I'm still a bit of a self-hosting fundamentalist myself, and I want to put the majority of my work into projects that're friendly to self-determination and small energy efficient servers at home.
But I'm tired of trying to "manifest" a reality where anyone can do this themselves. It's hard enough for me to do what I do, and I've been working my ass off for my entire life to get to where I am. Self-hosting is such a shitty term because it sorta implies that you do it all by yourself. Not only is that unrealistic, it's also a lot less fun.
I'm still trying to figure out what I want to build, let alone what to call it. I want to build slow-cluster software that's all about NAT traversal and good user interface instead of about scalability. I want to build something like the fediverse, software that can form circles of friends. Not a social media of URLs, but a homebrew web server infrastructure cleanly abstracted away from the hardware, abstracted away from the individual, and free to flow like water.
(Albiet slowly when it has to flow through the internet connection in grandma's basement 👵)
Maybe I want to make a homebrew "cloud" IaaSS (Infrastructure as a SelfService 😛) that server admins can operate with a couple friends. Whatever it is, I think it should combine the best aspects of both Federation and Clusters, while attempting to avoid the worst pitfalls of both.
So in the end, It's not Federation vs. Clustering...
It's
Federation 💘 Clustering
👶?
Tune in next time 😉
Comments